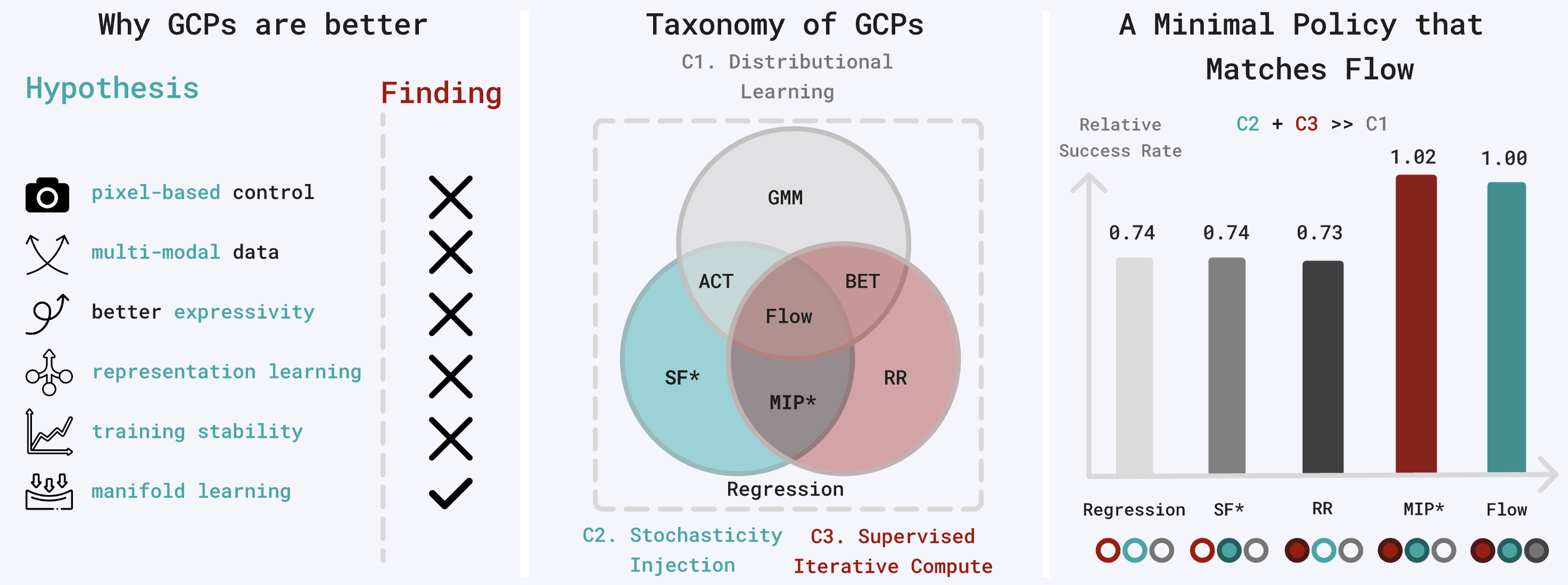
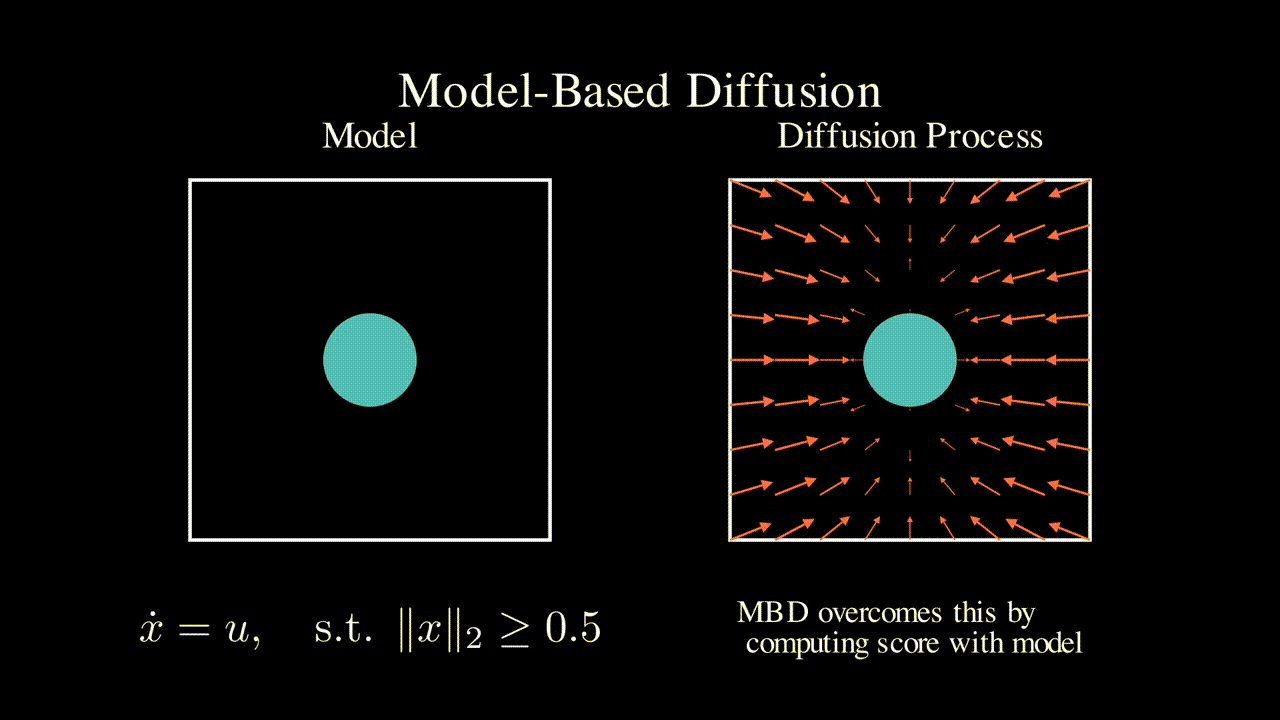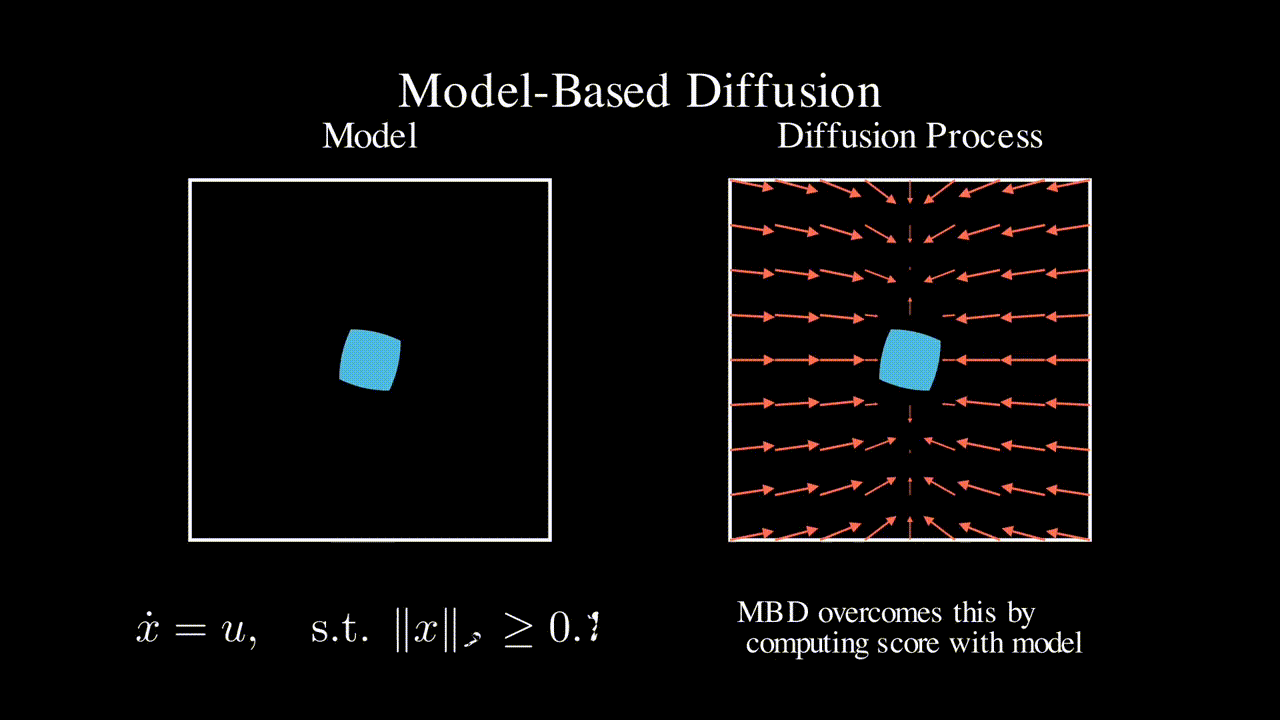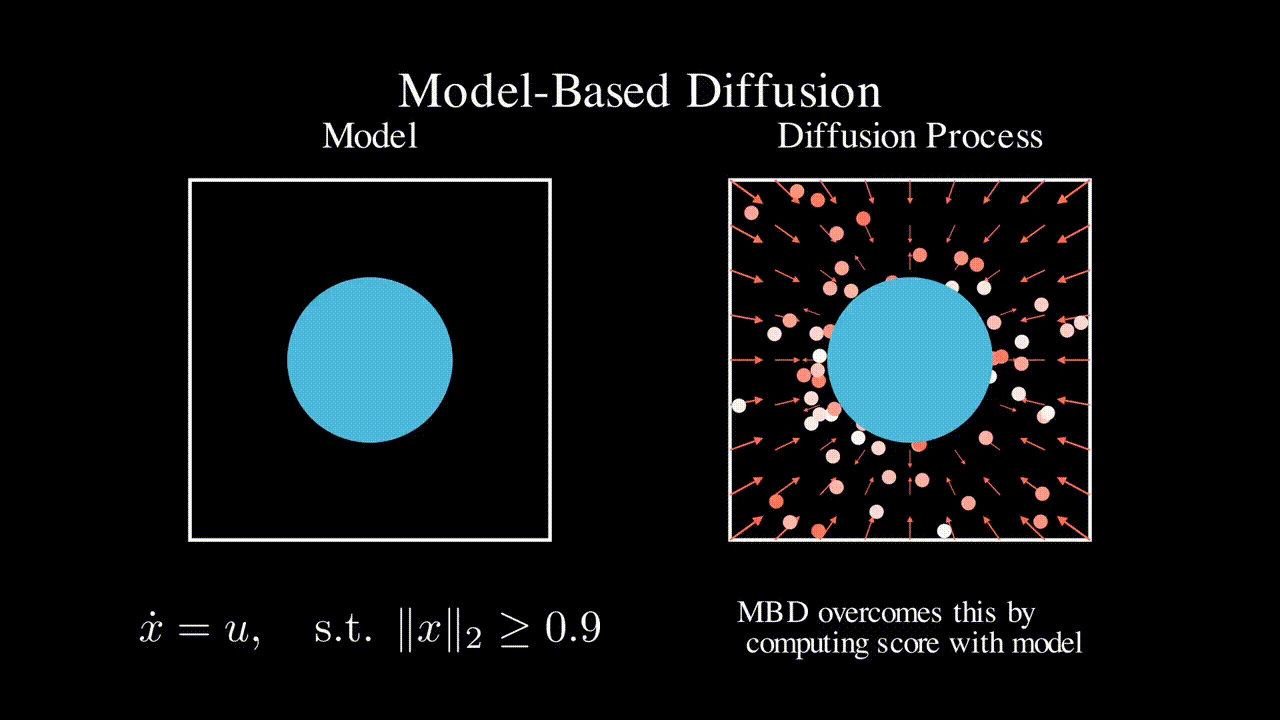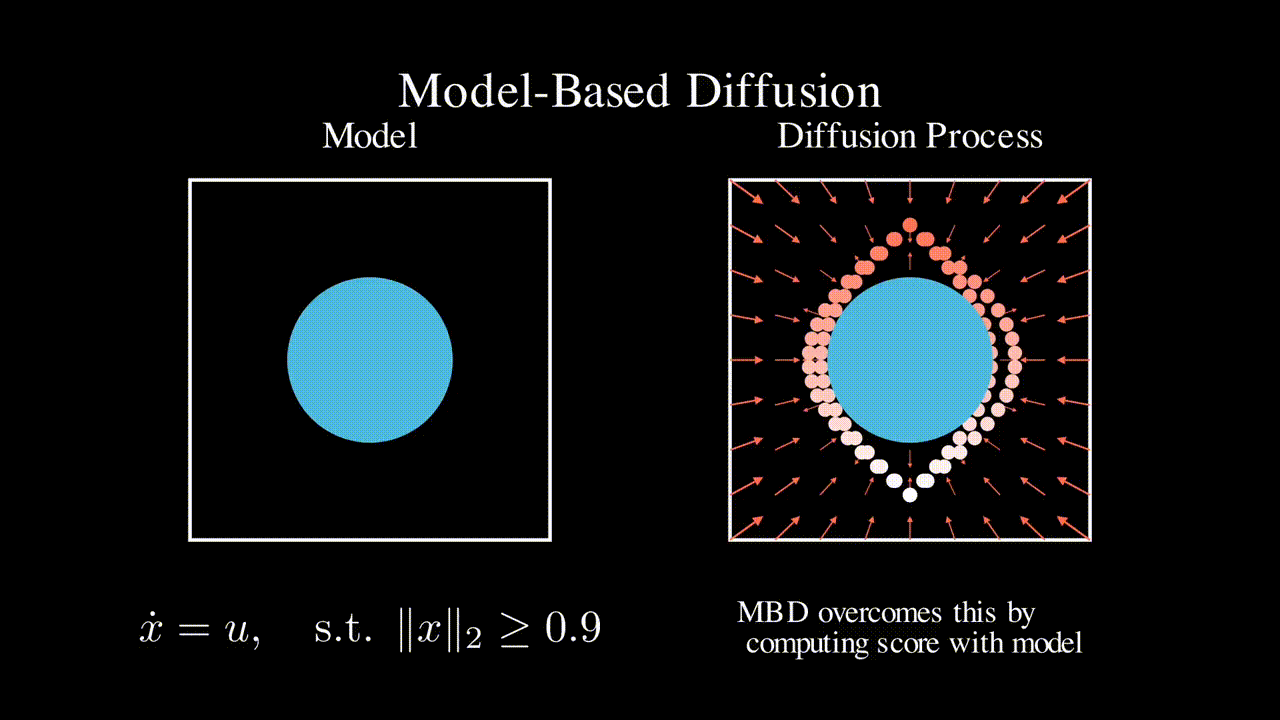
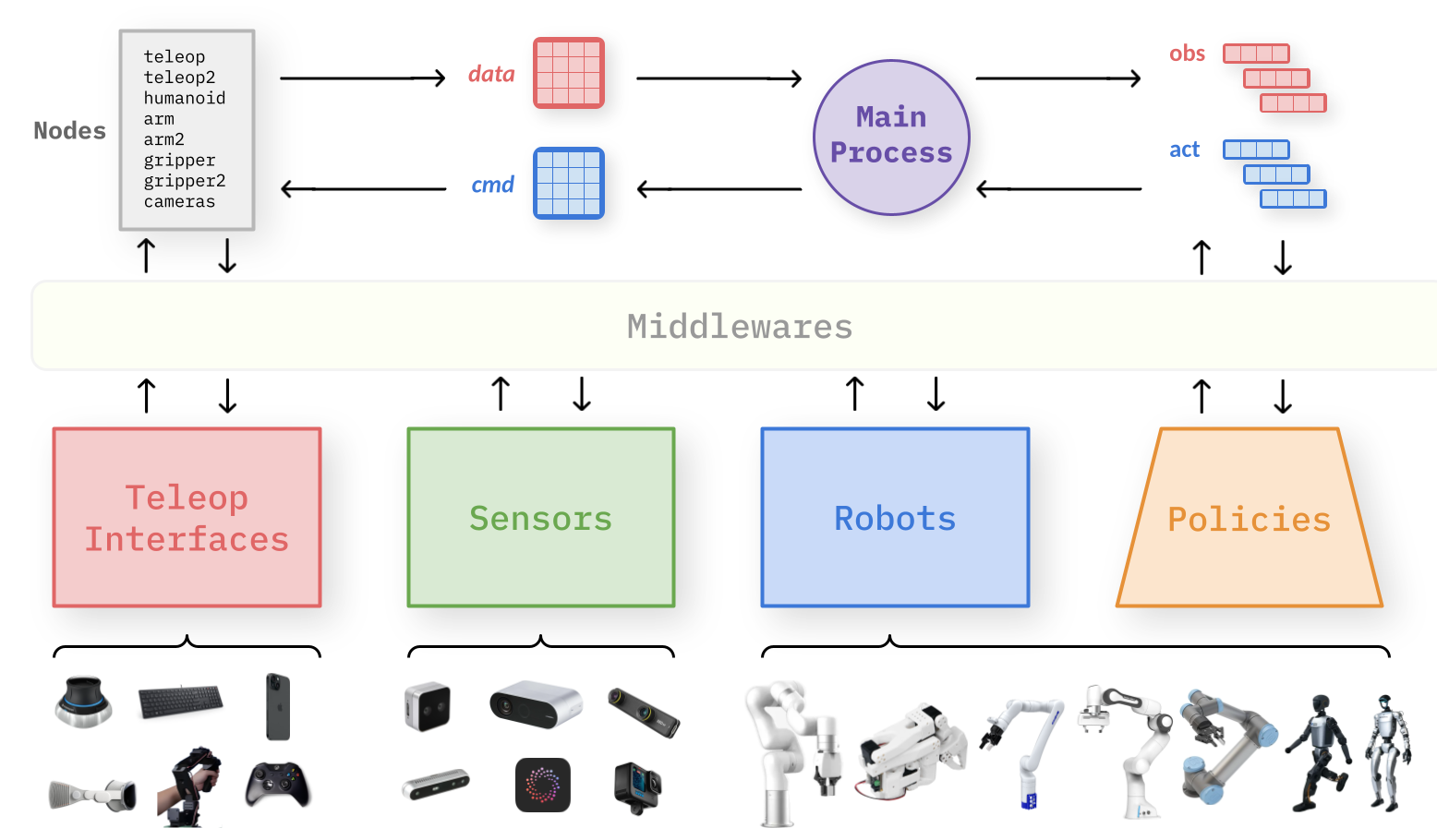
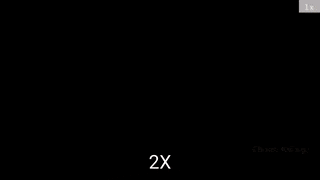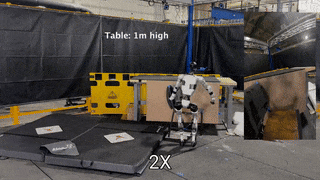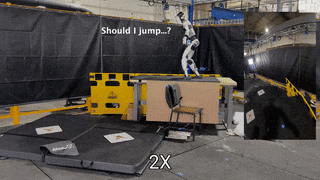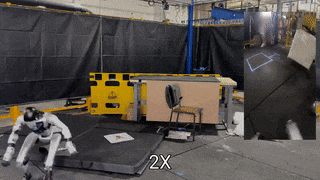OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
Conference on Robot Learning (CoRL), 2024
paper website dataset code IEEE Spectrum
TL;DR: OmniH2O provides a universal whole-body humanoid control interface that enables diverse teleoperation and autonomy methods.